Niin NATO:n tutkijoiden olisi pitänyt enää löytää oletettavasti pari sataa suomenkielistä ihmistä lukemaan satoja twiittejä ja kirjoittamaan niistä näkemyksenä, eritellen mitkä ovat loukkaavia. Ihan simppeli homma siis.Hälytyssanapohjaisen tutkimuksen suurin heikkous on siinä, että se vaatii valtavan suurta integriteettiä tutkijoilta. Valittujen hälytyssanojen manipuloinnilla pystytään helposti kääntämään tulos mustasta valkoiseen tai päin vastoin (ja en nyt siis edes vihjaa, että tässä yhteydessä olisi tehty mitään tämän kaltaista, puhun tuosta tutkimusmetodista puhtaasti yleisellä tasolla).
Tätä ongelmaa voidaan vähentää esimerkiksi käyttämällä riippumatonta raatia, joka lukee pistokoeluontoisesti satunnaisia osia aineistosta ja valitsee sieltä hälytyssanoja ja luokittelee ne systemaattisesti tyyliin erittäin loukkaava, jossain määrin loukkaava, neutraali. Kun lukijoita on monia, luokitukset tehdään heidän arvioidensa keskiarvojen perusteella, voidaan haaviin saada kohtuullisen hyvä valikoima, jonka perusteella sitten varsinainen aineiston massa siilataan tietokoneavusteisesti.
Toki tuo raportti kertoi miksi ja miten he käyttivät noita:
Ilmeisesti Twitter analyysin ongelma on siinä, että suurin osa suomalaisista ei sitä käytä, tai edes merkittävä osa suomalaisista, vaan mielipiteet laitetaan ennemmin Facebookiin yms. joita on hankalampi seurata, kun siellä on paljon eri ryhmiä joiden viestejä pitäisi verrata.The report is structured as follows. The literature review engages with the scholarly literature discussing definitions and methods of detecting abusive language on social media platforms, abuse of politicians online, misogyny online, and the use of bots for political purposes on Twitter. Having established this framework, we will describe our methodological approach for analysing the data, which combines social network analysis, bot detection, hate speech detection, and narrative analysis. This combination of quantitative and qualitative approaches is designed to identify instances when accounts coordinate to send abusive messages to politicians.
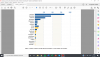
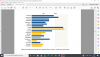
Tässä tutkimuksessa/raportissa on toki myös ihan kaavio siitä kuinka paljon tuli per henkilö. Haaviston saaman vihamielisen palautteen määrä yllätti, kun sitä oli yllättävän vähän. Prosentuaalisesti enemmän kuin muilla, mutta määrällisesti vähemmän, kun tälläkin palstalla käytettiin useita tuhansia rivejä siihen kun käydään läpi Haaviston toimia Al-Hol tapauksen yhteydessä.When analysing abusive messaging in the Finnish information space, the language barrier poses a challenge. One possible solution to this problem is to translate the dataset to English via machine translation, and then apply mainstream models optimised for the English language to the translated dataset. However, this approach would result in the loss of vital information, as translation services may distort the original text and its meaning. Therefore, in order to preserve the original text of abusive messages, we tried to avoid translation.
We decided to conduct hate speech analysis in the original Finnish language. To do so, we relied on the prepared dataset used in Knuutila et al (2019). This dataset contained approximately 2,000 tweets identified by the researchers as one of two classifications, either abusive or neutral.
Edelleen, tuon tutkimuksen voi kuka tahansa lukea ja siinä on alle 60 sivua varsinaista tekstiä, ei voi olla niin vaikeaa.