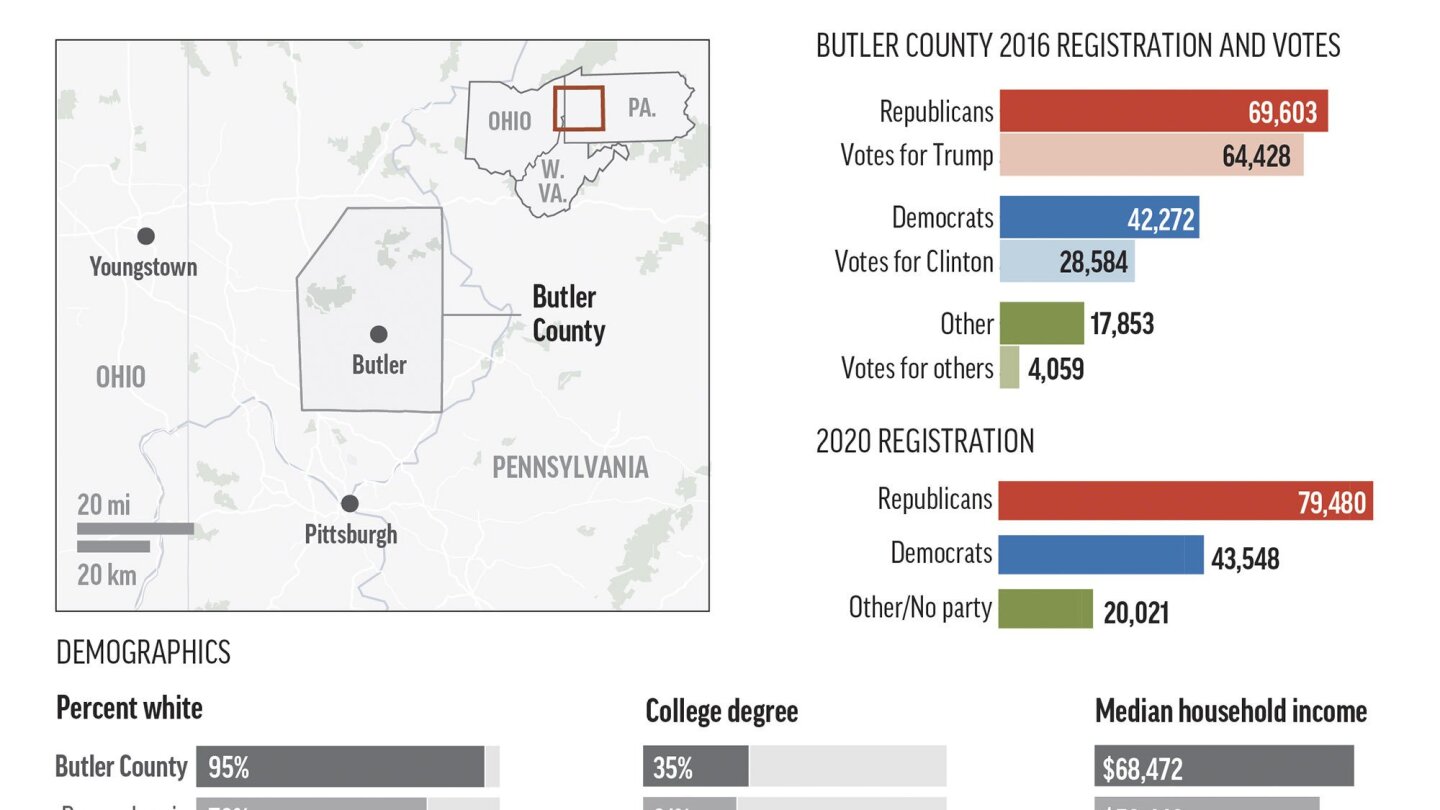
2016 edellisissä vaaleissa Clinton oli 27.10.2016 samojen tilastojen mukaan vieläkin isommalla etumatkalla Pennsylvaniassa. Silloin ennuste oli 50,2% Clintonille ja 43,8% Trumpille. Nythän ero näyttäisi olevan "vain" 52,3% Bidenille ja 47,0% Trumpille.Tästä saa hyvän käsityksen Pennsylvanian tilanteesta, aivan hyvältä näyttää:
Ennuste menee täysin ympäri jos Trump voittaa tämän osavaltion. Tuolta voi käydä kokeilemassa miten ennuste muuttuu, kun valitsee osavaltion voittajia. Pennsylvanian, jos klikkaa punaiseksi, niin Trump voittaa vaalit ennusteessa 69% todennäköisyydellä. Hämmentävää.

Explore The Ways Trump Or Biden Could Win The Election
Choose whether President Trump or Joe Biden will win each state in the 2020 presidential election and we’ll recalculate whether they have a path to 270 electoral votes and what their chance is of winning the Electoral College.